Bevor writing about our approach to geocoding news stories and elaborating on our key findings, i just wanted to do a quick post on some of our early experiments.
Geocoding based on the dateline: The easy route (to nowhere)
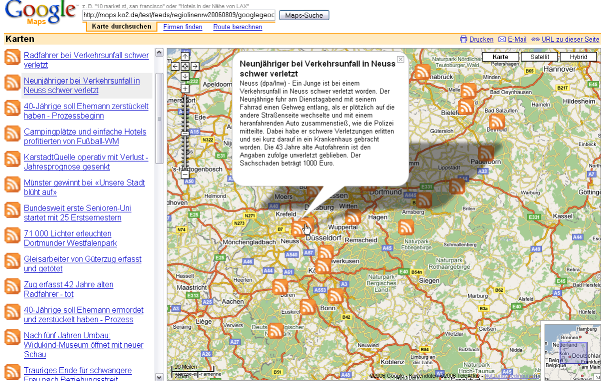 We could have taken the easy route and used the Google geocoder (or some other geocoder) and the city location(s) mentioned in the dateline of our stories to geocode the news. Generate some GeoRSS and/or KML feed and your done, i hear you say.
We could have taken the easy route and used the Google geocoder (or some other geocoder) and the city location(s) mentioned in the dateline of our stories to geocode the news. Generate some GeoRSS and/or KML feed and your done, i hear you say.
Well besides all kinds of reasons that are specific to the news agency business (e.g. that our customers are still often not used to RSS feeds, main modus of delivery of news agency news is still satellite and/or FTP push/pull, …) this also wouldn’t have been sufficient if we were a startup being completely free in its decisions.
It would have been sufficient if our goal would have been to generate some eye-candy (e.g. More or less arbitrarily stick pins into a map).
In fact i did exactly this back in early August 2006 in order to motivate and showcase the possibilities of geocoded news. You still can find the remains of that showcase over here. All in all it took me a couple of hours to do this showcase (adding generating flyovers with GoogleEarth, testing various other mapping libraries etc. this may add up to a couple of days).
But when being asked about the semantics of the chosen locations all we would be able to say:
Well, somebody decided that these cities should be part of the dateline.
Let me xplain why.
Dateline semantics
Originally the cities on the dateline stated the place where a story was written. Hence they had a clearly defined semantics. Unfortunately this semantic may be not the semantic that is of utmost important to the slew of the readers of the story.
But since in the early days of the news agencies the reporter had to be at the place of the scene in order to be able to report it the dateline locations most often coincided with the locations where the news actually happened.
Hence it was a relative good heuristic to associate the semantic with the locations mentioned in the dateline. But with the advent of telemedia this heuristic is no longer valid. Unfortunately this led to the common usage where the dateline contains a number of locations mixing both semantics without clearly indicating which location carries which semantic.
E.g an article reporting on Macworld might carry a dateline of San Francisco, Hamburg / San Francisco, Hamburg, or San Francisco / Hamburg.
So, geocoding news purely based on the dateline is a suboptimal idea. A better idea might be to use the geographic entities mentioned within the story.
Named entity recognition
But then how do you identify geographic entities in natural language text without too much manual work. This is typically a task solved by so called named entity recognition systems (or short NER) a subdiscipline of computational linguistics.
Unfortunately most of the NER software systems couldn’t hide their provenance from originally being implemented for “governmental uses” and are build by companies residing in Virginia. Typically this means that they are:
- (very) expensive
- available for english, arabic, persian, … with western-european languages other than english coming in as a distant n-th
Since we are publishing our regional news wires in german and we do not have that much money to spent, automatic extraction of named-entities by using named entity recognition software was postponed.
Actually, given my research background in AI, a number of my friends are working in computational linguistics and information extraction. Hence i tried to keep current with the state of the art in these systems in my spare time, and likely will give an overview on this in another article in this mini series. This article will also include an overview of the freely available web services for named-entity recognition i’m currently aware of.
In this context it would also be very interesting to learn from Adrian, which kind of algorithms everyblock uses when he says (in his Poynter interview)
Currently, we do that by crawling news sites and applying algorithms and human editing efforts.
Especially, since everyblock is using openlayers and tilecache, which are developed by Christopher Schmidt (and others) and sponsored by MetaCarta, a company specialising in identifying locations in text and providing fast access via specialised index structures. (Needless to say that Metacarta has an office in Vienna, VA and In-Q-Tel is one of their investors.)
Unfortunately the company did not reply to the various requests for information i placed via the web in the last year. I would be very intersted to learn more about their technology.